Tantek Çelik has thoughts on how microformats invert conventional approaches to problem-solving. (He invented the term “microformat,” so you can call him an expert on the subject.)
I want to talk about how the proposed bibleref microformat follows each of the assumptions Tantek lists.
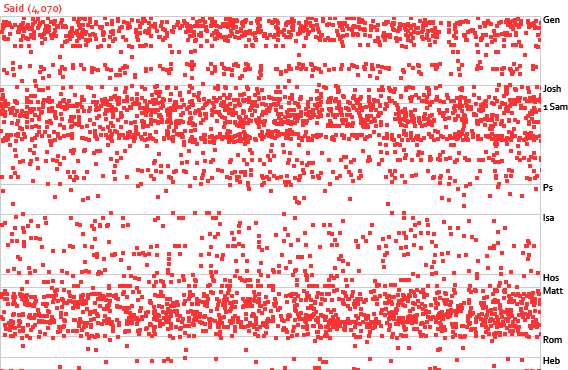
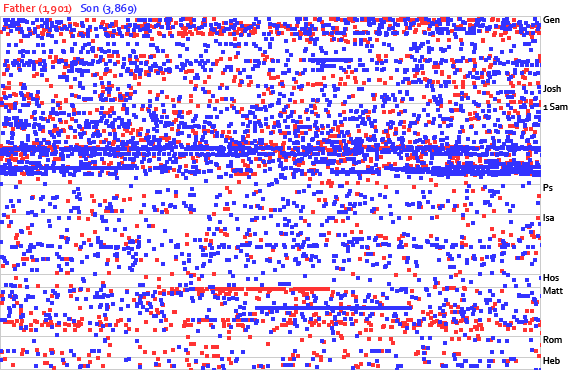
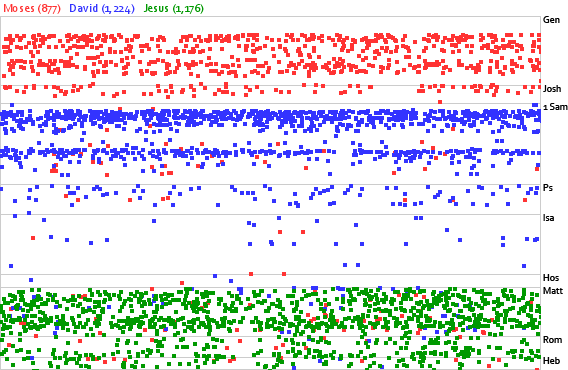
“Solve small specific problems rather than big problems…. By focusing on those rather than the big hard problems we get more done, and we learn important lessons (and perhaps even create a few building blocks) that make solving the harder problems easier.” An example of a big problem is the one posed by Axel about book-chapter-verse references not being unique identifiers because of different versification schemes. To my knowledge, only Logos has solved this problem, and they need a 57-MB data backend to support it. (57 MB != small problem.) It’s great that Axel brought up this problem; it’s an excellent one to solve, but it’s beyond the scope of a microformat solution—at least for now.
“Research existing data publishing behaviors and data formats, and then base designs directly on that research, rather than inventing new technologies for new spaces.” Online Bible-citing practices have pretty strong conventions, at least when they involve links to web Bibles: in general, either the reference itself is a link, or a word or phrase is a link. Bibleref handles both cases well. (The proposed specification doesn’t work as well when the title attribute of the <a> tag holds the text of the verse, as it sometimes does. I can’t think of an elegant way to handle this case; Chris Roberts’ WordPress plugin adds an empty <cite> tag. Would it be better to wrap the <cite> tag around the <a> tag or pursue an alternate solution? Hard to say.)
“Re-use existing vocabularies where possible, rather than inventing your own vocabulary/language (in contrast to XML culture).” HTML has a built-in tag for handling citations (<cite>), and using the class and title attributes as bibleref does falls both within the letter and even the spirit of those attributes. In contrast, an alternative way of specifying a Bible references is to invent a new protocol (<a href="bibleref:John.3.15">…</a>). This approach immediately breaks all browsers on the planet, rendering the links useless to the people who want to read the passages.
“Provide a solution to marking up data in existing web pages, rather than asking publishers to create machine-only side files in a new format.” Ah, external files. Recommendations that you not create a separate, “accessible” site for your content have a pragmatic underpinning: the flashy, inaccessible site will get all the developers’ attention and updates, while the accessible site gets updated occasionally or never. Similarly, even if you want to keep a running tally of all your Bible references, you’ll still need to indicate their existence in your primary content. Either you’ve just doubled your work, or you’re already using some sort of microformat to allow automated parsing.
“Solutions accessible to millions of hypertext web authors are better than solutions just for programmers.” Or, put another way, a markup solution is better than a programming solution. Anyone who knows HTML can add bibleref markup to their pages; you don’t also need to know Javascript or PHP or Ruby or anything else.
The central theme behind these assumptions: Microformats aren’t (and don’t need to be) perfect; they’re good enough. If you didn’t have any real-world constraints, you might not take the microformat approach. But real-world constraints are why I think Sean’s bibleref proposal is so effective: it doesn’t solve everyone’s problems, but it solves one problem well.
The distributed (bottom-up) nature of microformats provides their strength but also points to their primary weakness: discoverability. How many people are using bibleref? I have no idea, and I can’t find a search engine that will tell me. (Technorati has a Microformats Search, but it looks like they only index a few known formats from microformats.org.)
A Google search for [class-bibleref] turns up discussions about the microformat, but not much actual usage. (And I know more people have used it than turn up in the search results.) I want a way to find and aggregate people who are using bibleref. Most of the value in the bibleref microformat (in my opinion) comes from seeing how others are citing the Bible. None of us is in the search-engine business, unfortunately (unless you are—in which case, how about making elements’ class attributes searchable?), yet we still need some way to unobtrusively find and catalog microformat occurrences. In other words, the presence of the microformat itself should suffice for a search index; it’s not realistic to ask people to add other tags to their page to work around search engines’ current limitations.
But perhaps I’m getting ahead of myself. Or maybe Sean at Blogos has a grand plan that he’s going to unveil in January at the BibleTech08 conference.
Via ppk.