Browse 340,000 Bible cross references. Make the list better by voting on relevant or irrelevant verses.
For example, try Philippians 4:13 (“I can do all things through Christ who strengthens me”) or Isaiah 40:31 (“They shall mount up on wings like eagles”).
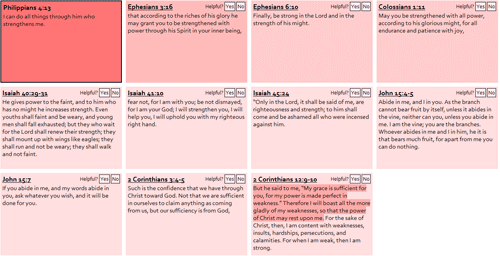
The interface is about as bare-bones as it gets: there’s a list of cross references for a single Bible verse, sorted by relevance (i.e., votes). You can browse to related verses, vote on whether each cross reference is relevant, and see (on external sites) the verses in different translations. It also prints nicely. There’s no way to suggest new cross references, though I may add that feature if there’s demand.
The data comes primarily from The Treasury of Scripture Knowledge (TSK) but blends other data, including the Topical Bible and Twitter Bible Search. All the copies of TSK on the web seem to descend from one source; I did some basic cleaning of the data and extracted the references. Then I blended the other data to weight some cross references more highly than others—that’s where the initial vote counts come from. (Incidentally, I only count around 380,000 cross references in TSK, lower than the usual count of 500,000 cross references you find when people talk about TSK. The lower number of cross references on this site–340,000–comes mostly from removing duplicates and combining adjacent verses.)
The 340,000 cross references in this data are a substantial number–most cross reference systems in print Bibles contain 50,000-100,000 cross references. While this list is more comprehensive, the tradeoff is that some of the cross references are less relevant than you find in print Bibles. As people use this site, however, the most-relevant verses should rise to the top.
The main limitation to the data is that the cross references always point from a single verse rather than from a range of verses: in other words, from Matthew 5:3 instead of from Matthew 5:3-11. Broader cross references—references that apply to a complete passage—are therefore missing from the data, limiting its usefulness somewhat.
The lack of an open, high-quality source of Bible cross references on the web has always bewildered me. This project is an attempt to remedy that deficiency. Feel free to download the raw cross-reference data (2 MB .zip, updated regularly with the latest vote counts) and use it in your projects.
Update April 12, 2010: Fred Sanders at Scriptorium Daily has a great introduction to the Treasury of Scripture Knowledge if you want more background on this work.



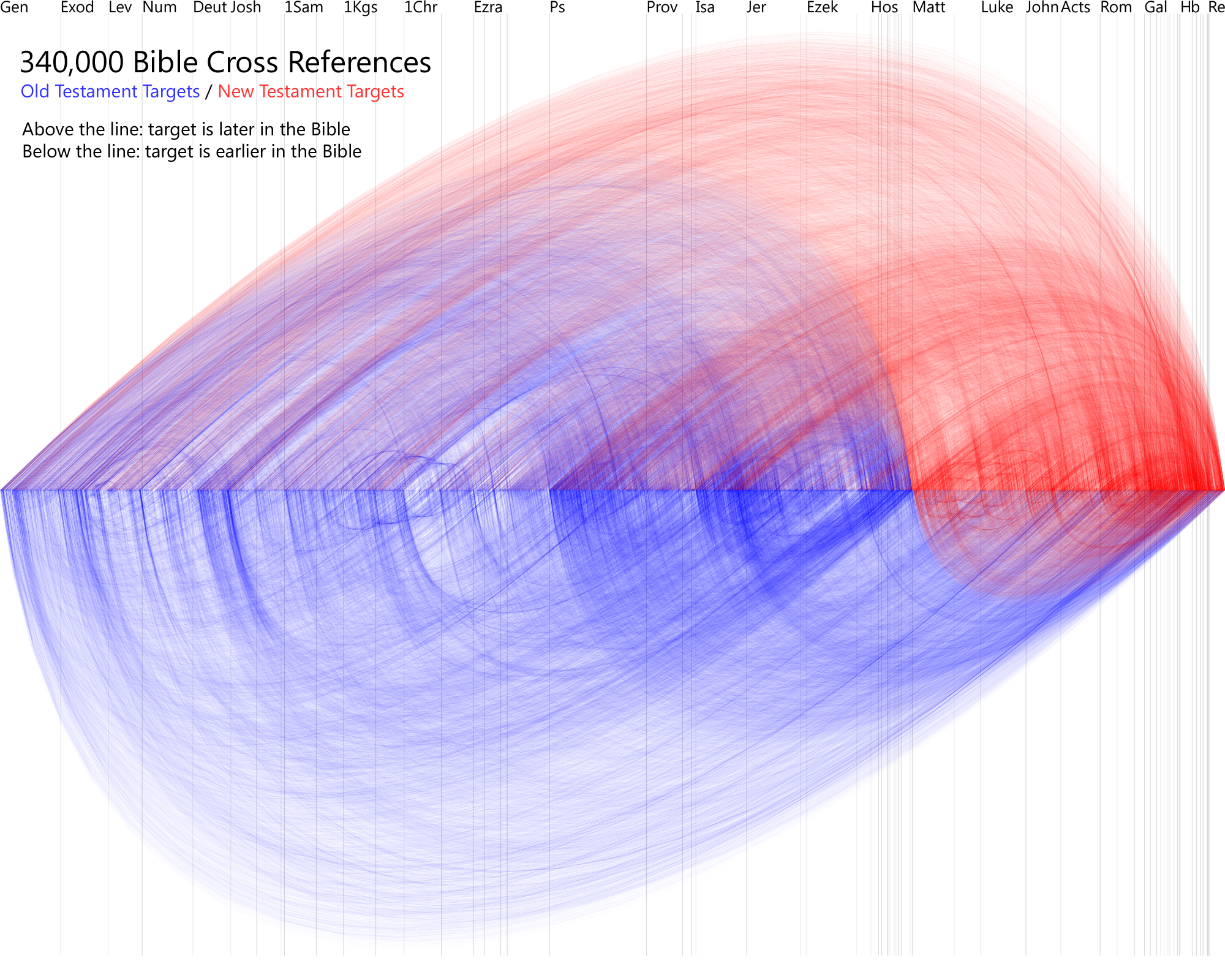





{kind=link}
{kind=link}