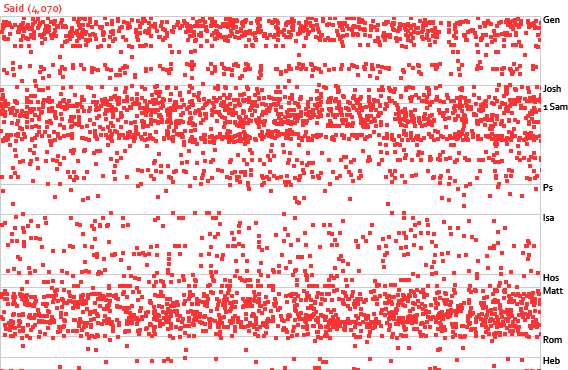
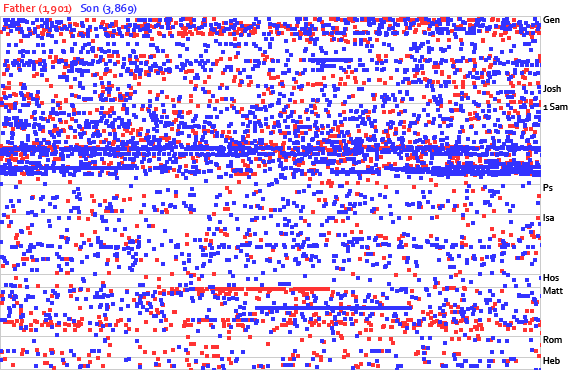
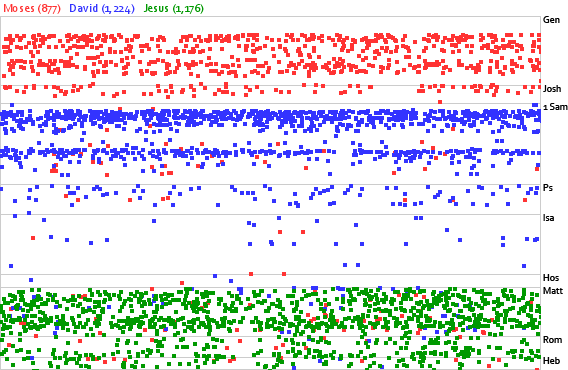
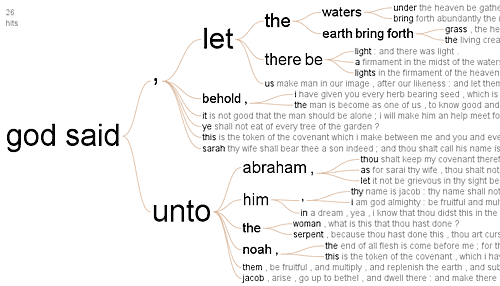
Sean from Blogos proposes a microformat for marking up Bible references on the web.
About Microformats
Microformats are a way of marking up semantic data in HTML without inventing new elements or attributes. For example, here’s how you might mark up geographic coordinates:
<div class="geo">GEO: <span class="latitude">37.386013</span>, <span class="longitude">-122.082932</span></div>
In this way, computer programs can figure out without any ambiguity that the above sequence of numbers refers to latitude and longitude. Browsers, for example, might automatically link the coordinates to Google Maps or your mapping application of choice. Firefox 3 is evolving along these lines.
Bible Microformat
I’ve been thinking for a while about the best syntax to use for a Bible microformat. The problem I kept running into was in coming up with the One True Representation of a Bible verse (i.e., is it “John 3:16” or “Jn 3:16” or “John.3.16” or something else).
Sean neatly sidesteps the problem with a “good enough” solution. He proposes a format akin to the following:
<abbr class="bibleref" title="John 3:16">Jn 3:16</abbr>
The crucial aspect is that it doesn’t matter exactly how you specify the Bible verse—once you do the hard part of indicating that a string of text is a verse reference (the class="bibleref"), any decent reference parser should be able to figure out which verses you mean. It’s so simple it’s brilliant.
Now let’s push it a little further.
I suggest that the microformat should take advantage of the underused and, in this case, semantically more meaningful <cite> tag rather than the <abbr> tag. You are, after all, citing the Bible.
<cite class="bibleref">John 3:16</cite>
However, you also have to account for people who link the verse to their favorite online Bible. You could double-up the tags:
<a href="…"><cite class="bibleref">John 3:16</cite></a>
But it’s messier than need be. Since the practice of linking is widespread, why not overload the <a> tag with the appropriate class:
<a href="…" class="bibleref">John 3:16</a>
Both <cite> and <a> have a title attribute in which you can place a human- (and machine-) readable version of the verse if you choose. The title is optional as long as the verse reference is the only text inside the tag. Indeed, a title is required only if the element’s text is ambiguous (a verse without a chapter and book, for example, or completely unrelated text). (The practice of not recording duplicate information is the Don’t Repeat Yourself principle.) For example:
<p>God <a href="…" class="bibleref" title="John 3:16">loves</a> us.</p>
Corner Cases
So how would you specify a Bible translation if a specific translation were germane to the citation’s context? (In theory, when you don’t specify a translation, people consuming the microformat could choose to see the passage in the translation of their choice, similar to how some people prefer to look up an address in Google Maps, while others prefer Yahoo Maps.) I’m sympathetic to the OSIS practice of indicating the translation first, followed by the reference. For example:
<cite class="bibleref" title="ESV: John 3:16">Jn 3:16</cite>
This practice follows the logical progression of going from general to specific:
[Implied Language] → Translation → Book → Chapter → Verse
The title is also human-readable, though it departs from the standard practice of placing the translation identifier after the reference.
Sean mentions two other cases of note: verse ranges (e.g., “John 3:16-17”) and compound verses (e.g., “John 3:16, 18, 20”). Personally, I see no reason for a biblerefrange attribute as he suggests. A bible reference parser should be able to handle a continuous range as easily as a single verse.
But compound verses present a more complex problem. How do you mark them up? The above examples all stand on their own, which is one of the principles of microformats—you parse the element and get everything you need. But let’s say you have the text “John 3:16, 18.” Treating the range as a unit is easy:
<cite class="bibleref">John 3:16, 18</cite>
Any parser will handle that text; though it could be ambiguous (do you mean John 3:16 and John 18?), in practice it rarely is. But what if you mark them up separately?
<cite class="bibleref">John 3:16<cite>, <cite class="bibleref">18</cite>
In this case, the “18” doesn’t communicate enough information to the parser. The parser could maintain a state and know that the previous reference was to John 3:16, but state requirements increase the parser’s complexity, which in turn defeats the purpose of the microformat in the first place. In such cases, then, I would argue that a title attribute is necessary:
<cite class="bibleref">John 3:16<cite>, <cite class="bibleref" title="John 3:18">18</cite>
Putting It All Together
Here’s my Bible microformat proposal:
Citing a Bible Verse without Linking to It
<cite class="bibleref">[reference]</cite>
Citing a Bible Verse while Linking to It
<a class="bibleref">[reference]</a>
Citing a Bible Verse Indirectly (or When the Text Is Ambiguous) without Linking to It
<cite class="bibleref" title="[reference]">[any text]</cite>
Citing a Bible Verse Indirectly (or When the Link Text Is Ambiguous) while Linking to It
<a class="bibleref" title="[reference]">[any text]</a>
Verse Reference Format
The [reference] in the above examples refers to a machine-parsable and human-readable representation of a single verse, a range of verses, or a series of verses. You should use unambiguous abbreviations if you use abbreviations. See Appendix C in the OSIS spec (pdf) for a list of possible abbreviations.
When you’re in doubt about whether the reference text is parsable, use the title attribute to encode a fuller representation. In particular, when the reference doesn’t include all the text necessary to produce an unambiguous book/chapter/verse reference, place an unambiguous reference in title.
About the title Attribute
The title attribute, when present, takes precedence over the contents of the element (<cite> or <a>). When the title is not present, the contents of the element are assumed to be the verse reference. The title attribute contains an unambiguous machine-parsable representation of the verse reference.
The attribute can also contain an optional translation identifier at the beginning of the value, followed by a colon. Appendix D in the OSIS spec (pdf) has a list of translation identifiers. For example:
<cite title="ESV: John 3:16">…</cite>
To be comprehensive, you would ideally include a language identifier (e.g., “en:ESV: John 3:16”) before the translation identifier. I would argue that a language identifier is only necessary if you’re using a non-standard abbreviation.
However, you should only include a translation identifier if it is important that your readers see a particular translation or language. Otherwise, you should allow the parsing software to use your readers’ preferred translation and language.
Here is a Perl regex for allowed formats in the title. $1 is the optional language identifier. $2 is the optional translation identifier. $3 is the verse reference, which is deliberately wide-open to accommodate many different reference formats.
title="([\w\-]+:)?([\w\-]+:)?\s*([^"]+)"