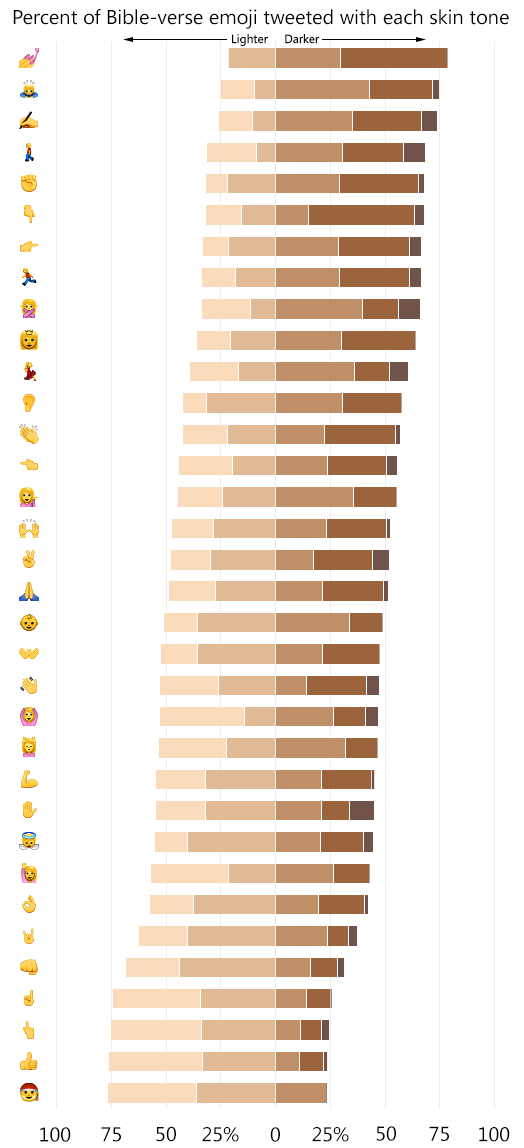
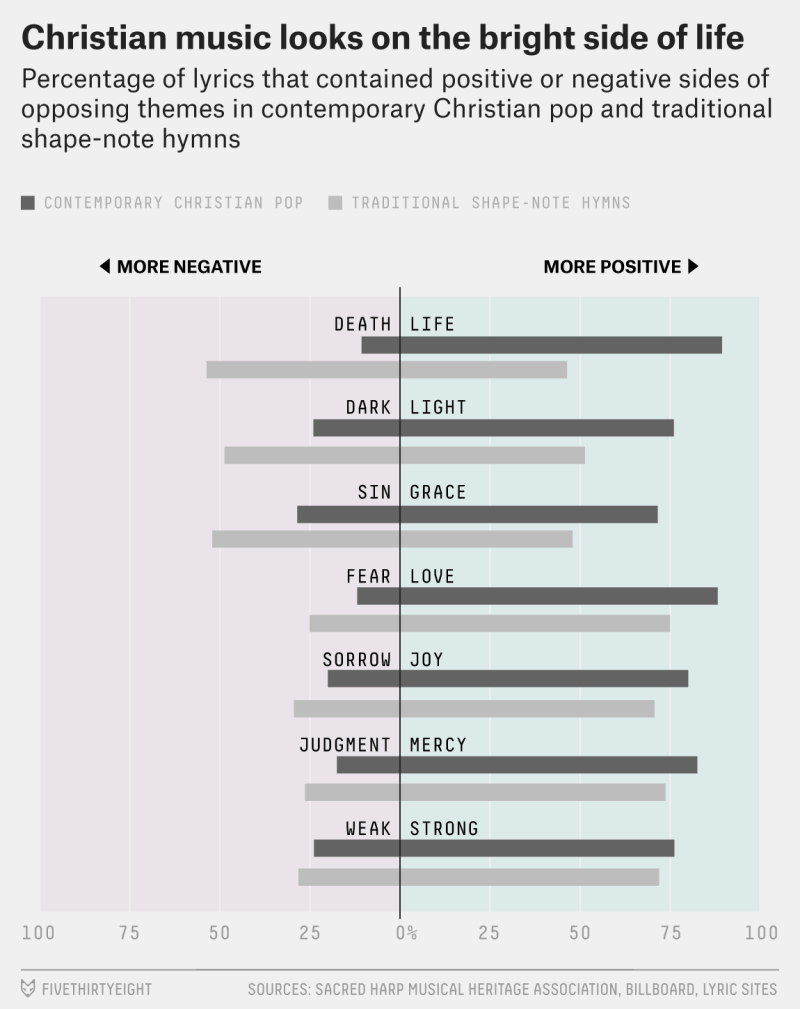
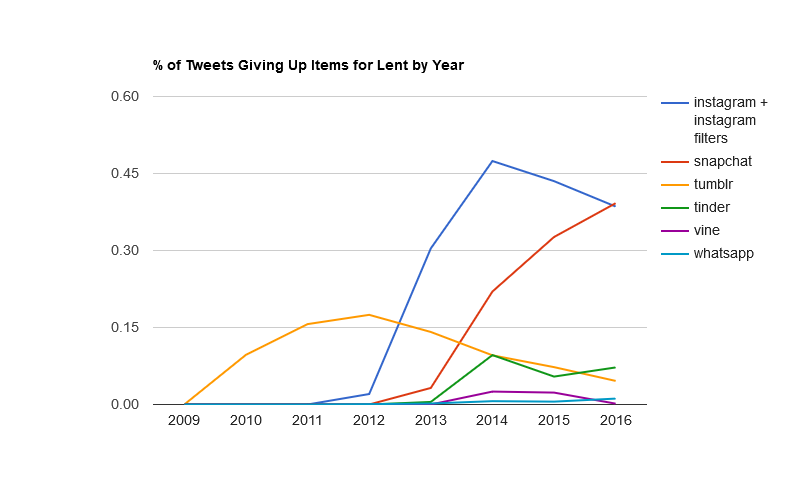
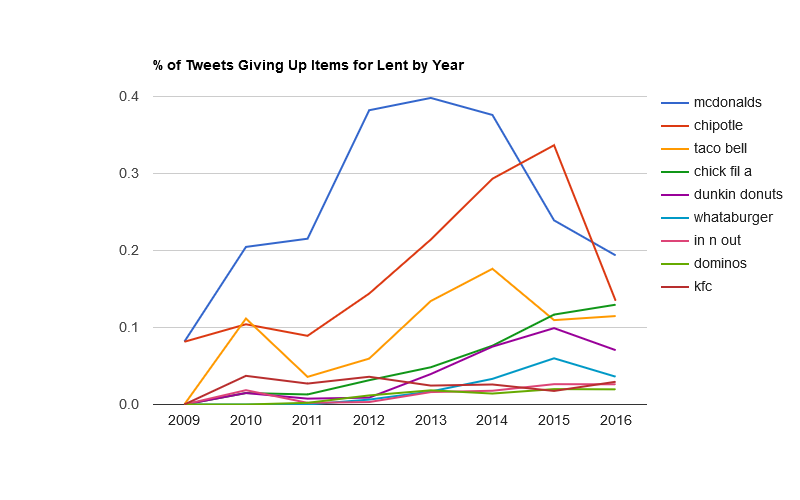
BigBible has been running a series of interviews called “Data and the Bible Online.” The latest is with me.
A recent interview in the series is with John Dyer. In part of his interview, he says, “I do worry that even for those of who value Scripture as part of their spiritual lives, it’s easy to confuse access to the Bible (i.e., having an app installed) with wisdom, maturity, or formation.” Just today I read This $1,500 Toaster Oven Is Everything That’s Wrong With Silicon Valley Design, with the tagline, “Automated yet distracting. Boastful yet mediocre. Confident yet wrong.” That tagline could well describe the future of digital Bibles.
In the article, Mark Wilson writes:
June [the oven] is taking something important away from the cooking process: the home cook’s ability to observe and learn. The sizzle of a steak on a pan will tell you if it’s hot enough. The smell will tell you when it starts to brown. These are soft skills that we gain through practice over time. June eliminates this self-education. Instead of teaching ourselves to cook, we’re teaching a machine to cook. And while that might make a product more valuable in the long term for a greater number of users, it’s inherently less valuable to us as individuals, if for no other reason than that even in the best-case scenarios of machine learning, we all have individual tastes. And what averages out across millions of people may end up tasting pretty . . . average.
Bible software can fall into these same traps, especially if an AI is involved. As Nicholas Carr likes to remind us, the more you automate something, the worse you become at it. Or, in Idiocracy terms:

Image: 20th Century Fox
On the other hand, I can’t say that the American church succeeded in developing believers’ “wisdom, maturity, and formation” even before digital technology increased the Bible’s availability and immediacy. Matthew Block writes in First Things that evangelicals in particular misapply the Reformation idea of Sola Scriptura:
many Christians seem to think saying Sola Scriptura is the ultimate authority somehow means it is my personal “solo” reading of Scripture that is authoritative. They reject the witness of the Church down through the ages in favor of a personal, private understanding of Scripture (which is not at all what the reformers meant by the term “Scripture alone”).
Digital Bibles will accelerate this process by emphasizing personal application and understanding of Scripture, possibly–but not necessarily–building a theological echo chamber in which an AI can present you internally consistent interpretations that nevertheless fall outside what most would consider the bounds of orthodoxy.
Dyer argues elsewhere that embodied practices could serve as one antidote to these virtualization trends seeping into culture and consequently the church. We already see a secular reaction against the always-connected mentality with organizations like Time Well Spent, and Dyer suggests that the church has the tools it needs to speak to people both discomfited and empowered by technology.
As the U.S. moves to a post-industrial Christianity likely characterized by increased fragmentation and polarization, and as gatekeepers shift–Christianity Today recently chronicled the rise of parachurch women’s ministries that counterpoint the decline of traditional Protestant denominations–developing (or rediscovering) a solid theology around embodiment and presence will become increasingly important to the church. I lament in my BigBible interview the paucity of formal theological education related to digital engagement: the need to equip pastors and others to understand and respond deeply to people’s relationship with a technology-mediated existence. I believe the American church will need to grapple with this relationship in the near future–if only because the wider culture will also struggle with it.